
Этот пост был первоначально опубликован мной на Инженерный блог Taboola.
Теперь, когда прошло больше года с момента нашего первый проект глубокого обучения появились, мы должны были продолжать двигаться вперед и поставлять лучшие модели, на которые мы способны.
Для этого было проведено множество исследований, в ходе которых были опробованы различные модели, от самых простых до мешок слов, ЛСТМ и Си-Эн-Эндля более продвинутых внимание, МДН и многозадачное обучение.
Даже самая простая модель, которую мы пробовали, имеет множество гиперпараметров, и их настройка может быть даже важнее, чем фактическая архитектура, которую мы в итоге использовали, — с точки зрения точности модели.
Хотя в области настройки гиперпараметров ведется много активных исследований (см. 1, 2, 3), реализация этого процесса настройки ускользнула от внимания.
Если вы пойдете и спросите людей, как они настраивают свои модели, их наиболее вероятным ответом будет «просто напишите скрипт, который сделает это за вас». Что ж, это легче сказать, чем сделать…
По-видимому, есть несколько вещей, которые вы должны иметь в виду при реализации такого скрипта.
Здесь, в Taboola, мы реализовали скрипт настройки гиперпараметров. Позвольте мне поделиться с вами тем, что мы узнали на этом пути…
Иногда используя научное обучение для настройки гиперпараметров может быть достаточно – по крайней мере, для личных проектов.
Для долгосрочных проектов, когда вам нужно отслеживать проведенные эксперименты, а разнообразие различных архитектур, которые вы пробуете, постоянно растет, этого может быть недостаточно.
Первая версия скрипта была простой, но удовлетворяла большинство наших потребностей. Требования были:
Легко запустить
Вы будете запускать этот скрипт много раз. Таким образом, должно быть как можно проще указать, какие эксперименты вы хотите провести.
В итоге мы получили следующий формат JSON:
{
"architecture": "lstm-attention",
"date-range": (("2017-01-01", "2017-04-01")),
"parameters": {
"num_of_attentions": (1, 2, 3),
"attention_hidden_layer_size": (32, 128, 256),
"attention_regularization": (0.1, 0.01, 0.001)
}
}
- архитектура: архитектура, которую вы хотите настроить, при условии, что ваш код поддерживает несколько типов
- диапазон дат: список кортежей, каждый из которых определяет временной диапазон, который будет использоваться для обучения модели. Каждый эксперимент будет выполняться один раз за диапазон дат.
- параметры: значения, которые нужно попробовать для каждого гиперпараметра. Наша первоначальная реализация поддерживала только конечный набор значений (поиск по сетке)
Скрипт случайным образом генерирует эксперименты из этого JSON.
Мы создали задание Jenkins, которое запускает скрипт на одной из наших машин с графическими процессорами, тем самым освобождая нас от необходимости использовать SSH.
Дополняйте эксперименты метриками
Наш процесс обучения генерирует множество показателей, таких как MSE, потери и время обучения. Вы можете выбрать то, что хотите, и они будут отображаться в результатах.
Сохраняйте результаты в облаке

Результаты сохраняются в виде CSV-файла в Google Cloud Storage, что позволяет нам запускать скрипт с любого компьютера и просматривать результаты с наших ноутбуков.
Результаты постоянно загружаются, поэтому нам не нужно ждать завершения всех экспериментов, чтобы начать проверку результатов.
Сами модели тоже сохраняются.
Эта первая реализация была самой важной.
Будучи простым, скрипт не сделал для вас ничего умного. В нем не указывалось, какие эксперименты выполнять — вам приходилось вручную определять ввод JSON для каждого запуска.
После многократного запуска скрипта вы начинаете понимать, какие значения работают лучше, чем другие. Это одна из самых важных вещей, которую мы получили от сценария — более глубокое понимание наших моделей.
Использование этого скрипта в первый раз дало нам большое улучшение — MSE снизилась более чем на 10%.
Когда вы проводите сотни экспериментов, лучшие из них обычно имеют незначительные различия. Откуда вы знаете, что это статистически значимо?
Один из способов решить эту проблему, если у вас достаточно данных, — обучить одну и ту же модель на нескольких диапазонах дат. Если одна модель лучше других во всех диапазонах дат, вы можете быть более уверены в ее реальности.
Допустим, сегодня июнь, и вы запускаете скрипт. Вот диапазоны дат, которые выберет скрипт:
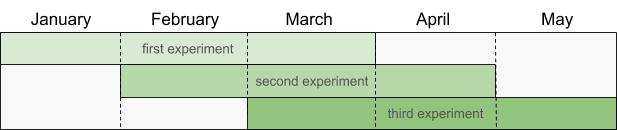
Обратите внимание, что скрипт выбирает новый набор диапазонов дат, если вы запускаете его в другом месяце. Это важно, так как в противном случае вы можете случайно переобучить свои модели из-за обширной настройки гиперпараметров.
У кого есть время проводить каждый эксперимент три раза? Приятно, что вы можете получить надежные результаты, но это означает, что в конечном итоге вы будете проводить меньше различных экспериментов.
В следующей версии скрипта эта проблема решена за счет поддержки нового режима работы:
- Используется только один диапазон дат
- Диапазон дат содержит данные только за один месяц.
- Обучение ограничено меньшим количеством эпох
Но коррелируют ли результаты с тем, что мы получили бы, если бы использовали больше данных и эпох?
Чтобы ответить на этот вопрос, мы провели несколько экспериментов, в каждом из которых использовалось разное количество данных в диапазоне от одной недели до трех месяцев. Мы обнаружили, что один месяц был хорошим компромиссом между MSE и временем обучения.
(Вы заметили, что мы использовали скрипт настройки гиперпараметров для настройки скрипта гиперпараметров? Насколько это круто?)
Чтобы выяснить, каким будет правильное количество эпох, мы проанализировали MSE на TensorBoard.
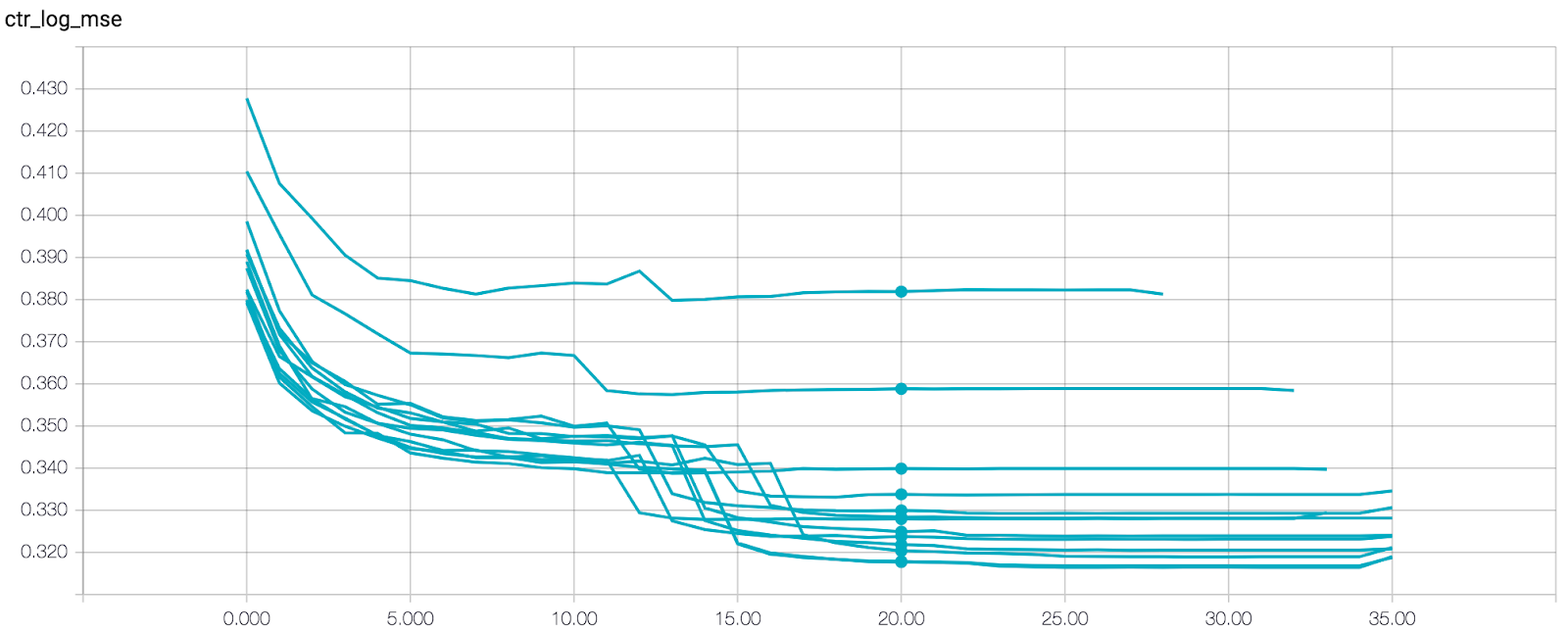
Каждый график на графике представляет собой другую модель, обученную на различном количестве данных. После 20 эпох все модели почти сошлись, так что можно смело останавливаться на достигнутом.
На этом этапе мы решили, что скрипт должен выбрать значения гиперпараметров за вас. Мы начали с гиперпараметров, связанных со скоростью обучения: начальная скорость обучения, коэффициент затухания, количество эпох без улучшения для ранней остановки и т. д.
Почему скорость обучения?
- Это существенно влияет на время обучения. Мы должны сначала установить хорошую скорость обучения, как с точки зрения точности, так и с точки зрения времени обучения, прежде чем настраивать все остальное.
- Некоторые предлагают он контролирует эффективную мощность модели более сложным образом, чем другие гиперпараметры, поэтому, возможно, лучше начать с него.
В новом режиме скрипта используются жестко заданные диапазоны значений, приемлемые для наших моделей.
Затем последовало следующее требование:

Следующая версия скрипта сделала именно это: при наличии имени архитектуры он автоматически генерировал для вас эксперименты. Вам не нужно указывать какие-либо значения гиперпараметров.
Хотя это хуже, чем случайный поиск в некоторые случаипоиск по сетке легче анализировать: каждое значение используется в нескольких экспериментах, поэтому легко выявлять тенденции.
Поскольку мы уже интуитивно поняли, какие значения работают лучше, пришло время реализовать случайный поиск. Это помогло скрипту найти лучшие гиперпараметры.
На этапе исследования любого проекта машинного обучения настройка гиперпараметров может выполняться вручную. Однако, если вы хотите вывести проект на новый уровень, очень эффективно автоматизировать процесс. В этом посте я описал некоторые небольшие штрихи, которые мы внедрили в процесс автоматизации. Что-то может быть для вас полезным, что-то нет. Напишите в комментариях, если вы нашли какие-то другие интересные вещи, которые могут быть вам полезны.