
На прошлой неделе у меня была возможность посетить Ежегодная конференция TCE. Он был посвящен как теоретическим, так и практическим аспектам глубокого обучения. Как практик глубокого обучения, которому нравится понимать, почему вещи работают (или не работают), я знал, что найду конференцию интересной.
Я решил быть хорошим гражданином и поделиться с вами основными моментами. Имейте в виду, что под основными моментами я подразумеваю вещи, которые мне субъективно показались интересными. Это не будет подробным подведением итогов конференции.
С первым докладом выступил проф. Нати Сребро из Чикагского университета. Одной из проблем, которую он пытался решить, было понимание того, что заставляет сеть хорошо обобщаться, несмотря на то, что класс моделей имеет чрезвычайно высокую пропускную способность.
Главный вывод заключался в том, что алгоритмы оптимизации (SGD, Adam и т. д.) вносят индуктивное смещение. При выборе одного из доступных алгоритмов процесс обучения будет направлен на поиск конкретного типа решений.
Например, хотя Адам тренируется быстрее, чем SGD (потери при обучении минимизируются быстрее), эмпирические эксперименты показывают, что SGD имеет тенденцию лучше обобщать (потери при тестировании меньше).
Он показал еще один интересный пример сети FF без какой-либо функции активации. Индуцированный класс моделей представляет собой линейные функции: несколько слоев эффективно схлопываются в один слой. Он показал, что при использовании разных паттернов связи между слоями мы получаем решения разного качества, хотя класс моделей остается прежним. Это связано с индуктивным смещением, которое мы вносим в процесс обучения, определяя шаблоны соединения.
В конце концов, мы должны помнить, что глубокое обучение не может просто найти оптимальное решение с точки зрения обобщения. волшебно – даже если у нас много данных. Это причина использования разных архитектур и разных алгоритмов оптимизации для разных задач обучения. В противном случае можно было бы использовать простые архитектуры FF с простым SGD.
В следующем выступлении Захари Чейз Липтон из Университета Карнеги-Меллона обсудил ряд работ, каждая из которых направлена на повышение эффективности обучения на основе человеческого взаимодействия.
В настройке RL (обучение с подкреплением) модель подвергается воздействию огромного количества примеров во время обучения. Агент может выбирать, как исследовать пространство состояния-действия. Цель состоит в том, чтобы изучить, какую награду принесут возможные действия при использовании известных хороших действий.
Этот компромисс может быть решен с помощью простого \(\эпсилон\)-жадный алгоритм: с вероятностью \(1 – \эпсилон\) агент выбирает действие, которое, как ожидается, принесет максимальное вознаграждение, и с вероятностью \(\эпсилон\) выбирается случайное действие. Обычно отжигают \(\эпсилон\) во время тренировки.
Этот алгоритм явно не является оптимальным. Например, предположим, что в текущем состоянии у агента есть десять действий на выбор, и он знает, что действие А является лучшим с вероятностью 0,5, так же как и действие Б. Все остальные действия плохие с вероятностью 1,0. Если он хочет исследовать, было бы разумнее случайным образом выбирать только между A и B.
Это мотивация алгоритма выборки Томпсона. Чтобы это работало, модель должна оценивать неопределенность. Один из способов сделать это — использовать байесовскую нейронную сеть. В этой модели вместо чисел для весов модели мы используем распределения. На прямом проходе мы делаем выборку из распределения весов, чтобы получить прогноз точечной оценки. На обратном проходе мы обновляем параметры распределения весов, используя прием репараметризации. Во время тестирования мы делаем вывод путем многократной выборки из распределений весов, таким образом получая распределение по прогнозам.
Еще одна интересная тема заключалась в том, как выбрать, какие примеры аннотировать. Одна из идей заключалась в том, чтобы использовать иерархию меток и активно выбирать бинарные вопросы для аннотатора. Это похоже на игра двадцать вопросов.
Выступление закончилось интересным вопросом, о котором следует помнить: наборы данных, как правило, имеют более длительный срок хранения, чем модели. При активном аннотировании набора данных с использованием конкретной модели будет ли этот набор данных лучше для будущей модели по сравнению со случайной аннотацией? Ответ сомнительный.
Профессор Михал Ирани из Научного института Вейцмана рассказал об использовании глубокого обучения для сверхвысокого разрешения.
Она рассказала о повторениях внутри естественных изображений — как внутри одного и того же изображения, так и в разных масштабах этого изображения. Это важно для сверхвысокого разрешения, поскольку можно уменьшить заданное изображение, найти повторения в двух изображениях, а затем научиться увеличивать исходное изображение.
Этот подход использовался в прошлом с использованием классических алгоритмов, и в этом докладе Михал рассказал, как это сделать с помощью глубокого обучения, используя только данное изображение.

В ее подходе изображение сначала уменьшается в масштабе. Затем модель CNN обучается восстанавливать исходное изображение. Эта же модель затем используется для масштабирования исходного изображения.
Михал утверждает, что это внутренний обучение – в отличие от внешний обучение тому, где суперразрешение обучается с использованием набора данных — может работать с моделью меньшего размера. Это связано с тем, что одно изображение имеет более низкую энтропию по сравнению со всем набором данных. Следовательно, тренировочный процесс завершается менее чем за восемь секунд, что впечатляет.
Профессор Лиор Вольф из Тель-Авивского университета и FAIR описал генеративные модели в различных областях. В частности, он подробно описал модель, которая может преобразовать музыкальное произведение, исполняемое на одном инструменте, в исполнение на другом.
![]()
Идея архитектуры заключается в использовании модели автоэнкодера для всех типов инструментов. Компонент кодировщика является общим для всех инструментов, в то время как декодер уникален для каждого из них.
Во время обучения модель каждый раз получает другой пример инструмента. Он использует унифицированный кодировщик и специальный декодер прибора и пытается реконструировать сигнал.
Поскольку энкодер является общим для всех инструментов, он должен научиться кодировать информацию, не зависящую от реального инструмента. Таким образом, закодированная информация будет содержать только музыкальную информацию, например который ноты играются, а не как они звучат. Задача декодера — заставить их звучать как конкретный инструмент.
Хотя в теории это звучит хорошо, на практике кодер учится выделять разные подпространства скрытого пространства для разных инструментов. Это нежелательное поведение, потому что закодированную гитару нельзя будет декодировать в флейту, поскольку декодер флейты не был обучен входным данным из этого подпространства.
Чтобы решить эту проблему, они ввели потерю путаницы в домене: если модель способна различать инструменты, использующие закодированный вектор, потери будут высокими.
Ури Шалит из Университета Технион рассказал об интересной области, мало известной многим практикам, — казуальном умозаключении. Одним из примеров может быть использование модели для прогнозирования того, какое лекарство будет лучше для данного пациента.
Теоретически мы могли бы обучить модель, используя медицинские записи. Но что, если более состоятельные пациенты склонны чаще принимать лекарства А, чем Б? Если мы не измеряем богатство, любой алгоритм может быть обманут, думая, что A лучше, чем B, даже если это не так. В этом случае богатство называется конфаундером.
Нет никакого способа узнать правду, если мы не проведем РКИ (рандомизированные контролируемые испытания). Таким образом, мы можем случайным образом назначать лечение пациентам, тем самым устраняя влияние искажающих факторов. К сожалению, во многих сценариях реальной жизни проведение экспериментов является дорогостоящим или невозможным, помимо прочего, по этическим причинам.
Затем Ури представил TARNet (сеть представительств, не зависящих от лечения):
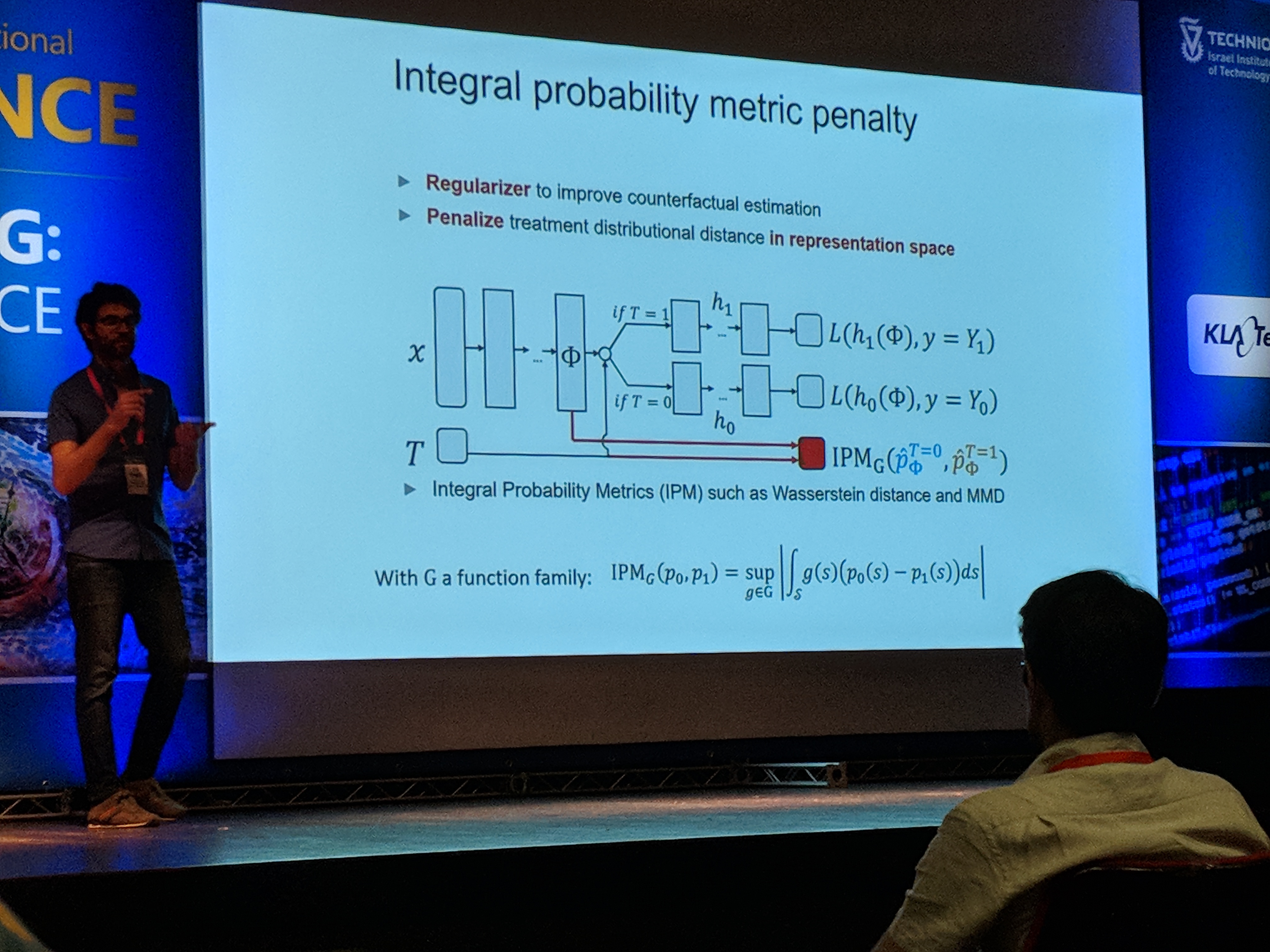
Первая ключевая идея архитектуры заключается в том, что каждый пример обрабатывался либо обработкой, \(Т = 0\) или лечение \(Т = 1\). Следовательно, после преобразования в представление \(\Фи\)один из двух путей выбирается на основе \(Т\)который можно рассматривать как переключатель.
Вторая ключевая идея заключается в том, что распределения выборок двух вариантов лечения различаются. Таким образом, если мы хотим сделать вывод о результате лечения \(Т = 1\) пациенту в тренировочном наборе, который получил \(Т = 0\) у нас были бы проблемы, поскольку это было бы экстраполяцией.
Чтобы решить эту проблему, модель поощряет представление \(\Фи\) действовать так, как будто дистрибутивы одинаковы. Другими словами, модель имеет регуляризацию в виде штрафной обработки расстояния распределения в пространстве представления.
В конце выступления Ури представил еще одну модель — CEVAE (Casual Effect Variational Autoencoders). Я очень люблю вкусы VAE, поэтому упоминаю об этом. Если вам тоже нравятся такие модели, я рекомендую вам прочитать об этом.
В следующем выступлении Дэниел Судри из Университета Технион упомянул несколько интересных идей. Во-первых, он объяснил, почему иногда, когда модель начинает переобучать (увеличиваются потери при тестировании), фактическая точность тестирования может все еще улучшаться.
Возьмем, к примеру, логистические потери. После тренировки на \(т\) эпохи, вектор весов \(ш\) будет стремиться \ (\ шляпа {w} \ cdot log
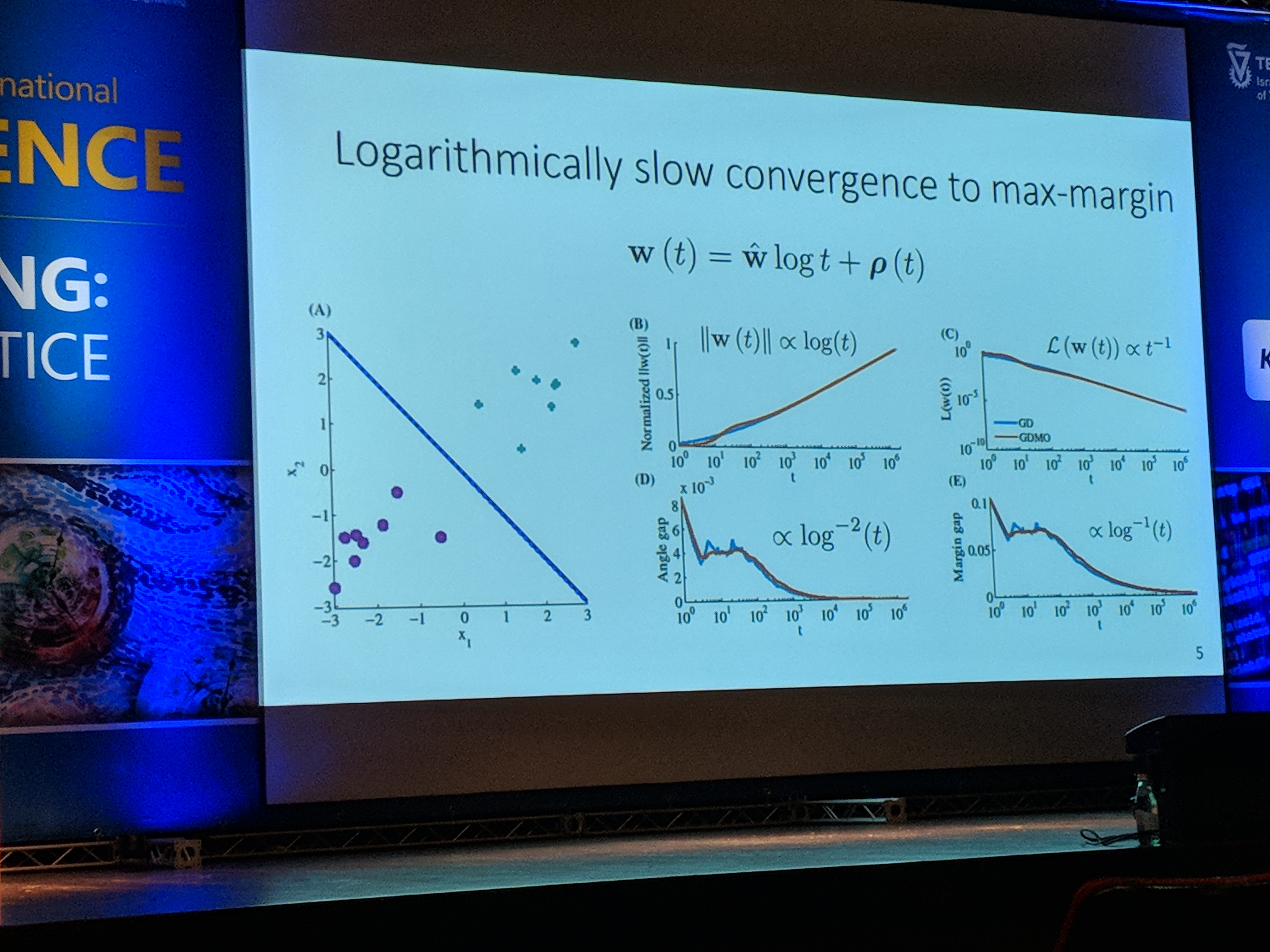
Кроме того, потери при тестировании увеличиваются по скорости \(\Омега(журнал(т))\). Это связано с тем, что некоторые примеры в тестовом наборе классифицированы неправильно. Поскольку длина \(ш\) стремится к бесконечности, потери ошибочно классифицированных тестовых примеров также будут стремиться к бесконечности. Это верно даже при том, что модель может повысить точность тестирования.
В последнем выступлении Йоав Голдберг из Университета Бар-Илан попытался пролить свет на различные разновидности архитектуры RNN и на что они способны.
Во-первых, он показал разницу в производительности между LSTM и CBOW в трех простых задачах: предсказание длины предложения, включение слов (находится ли w внутри данного предложения) и порядок слов (находится ли w1 перед w2 в данном предложении).
Для предсказания длины лучше использовать LSTM. Интересно, что CBOW делает достойную работу. На первый взгляд кажется, что некоторые слова могут предсказать длину предложения: может быть, некоторые слова имеют тенденцию быть в более длинных предложениях?
Но, подумав еще раз, оказывается, что чем длиннее предложение, тем меньше становится норма среднего вложения слов. Это дает модели возможность прогнозировать длину предложения.
CBOW лучше справился с задачей сдерживания слов, но LSTM показал преимущество в задаче порядка слов.
Интересно, что LSTM не полагается на естественность языка, в отличие от модели с пропуском мыслей.
Далее Йоав показал, что LSTM, в отличие от GRU, умеет считать:
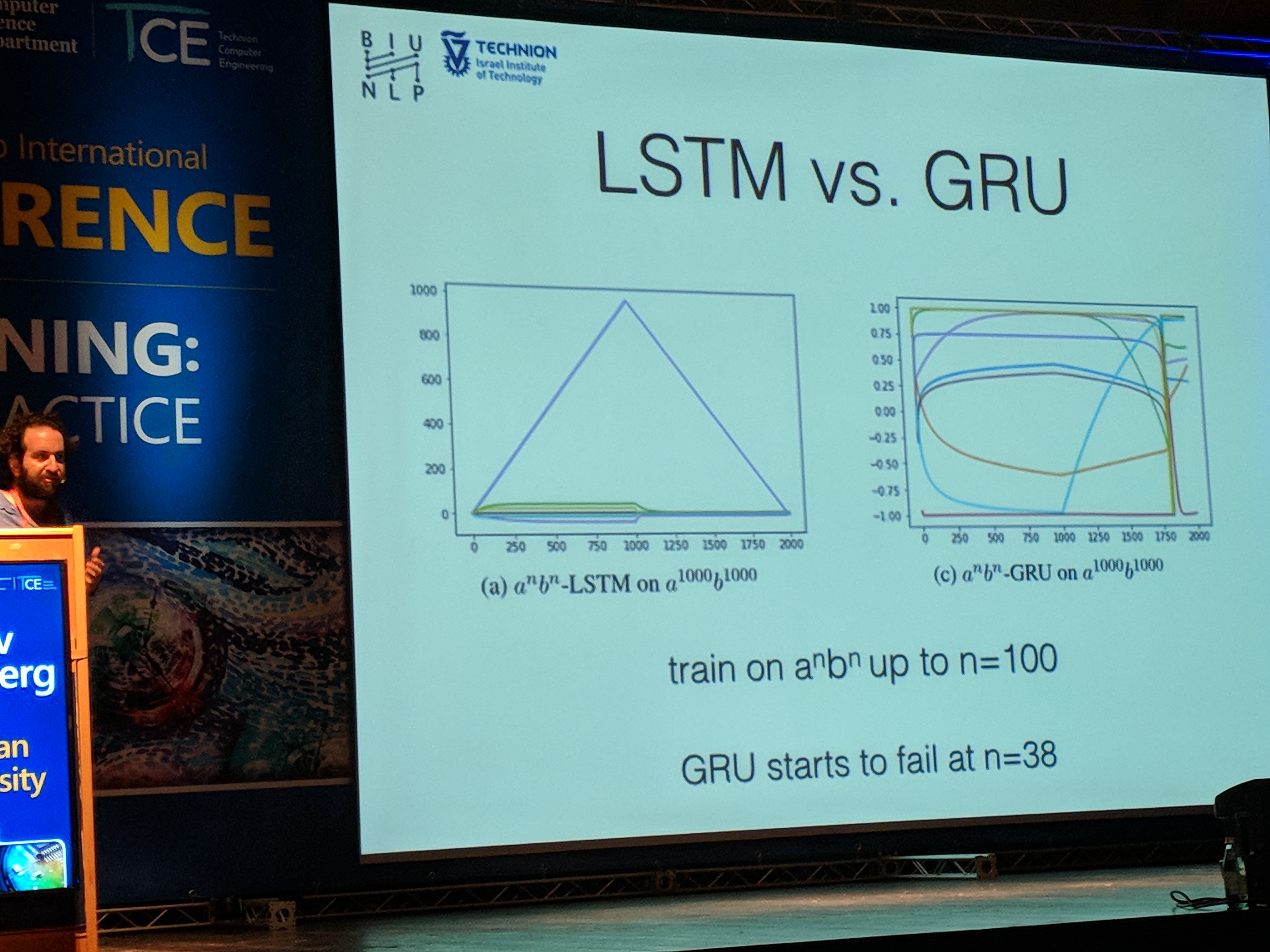
При обучении с использованием скрытого размера состояния 10 мы видим, что в LSTM одно из измерений научилось считать. Это возможно из-за стробирующего характера модели: можно вручную установить значения весов, чтобы включить подсчет.
Хотя задача подсчета довольно проста и обычно отличается от того, что выполняет типичное приложение глубокого обучения, интересно понять некоторые ограничения строительных блоков, которые мы используем в нашей повседневной жизни моделирования.

Конференция завершилась панелью. Это было и забавно, и наводило на размышления, так как большинство выступавших знали о шумихе, которую DL приобрела за последние годы.
Многие из них считали, что DL привлекло слишком много внимания, и классический ML тоже заслуживает внимания. Однако они все равно участвуют в игре DL — теоретически или практически. Я думаю, что каждый практикующий должен помнить об ограничениях DL, и что не все работает как черная магия.
Это особенно важно в критически важных приложениях, таких как медицинские и образовательные области, а также в приложениях, где мы не хотим, чтобы модель была предвзятой, например, в банковской области.