
DeepNash учится играть в Stratego с нуля, сочетая теорию игр и глубокое RL без моделей.
Игровые системы искусственного интеллекта (ИИ) вышли на новый уровень. Стратего, классическая настольная игра, более сложная, чем шахматы и го, и хитрее, чем покер, теперь освоена. Опубликовано в Наукамы представляем ДипНэшагент ИИ, который изучил игру с нуля до уровня эксперта-человека, играя против самого себя.
DeepNash использует новый подход, основанный на теории игр и глубоком обучении с подкреплением без моделей. Его стиль игры сходится к равновесию Нэша, а это означает, что его игру очень трудно использовать противнику. На самом деле настолько сложно, что DeepNash вошла в тройку лучших за всю историю среди экспертов-людей на крупнейшей в мире онлайн-платформе Stratego, Gravon.
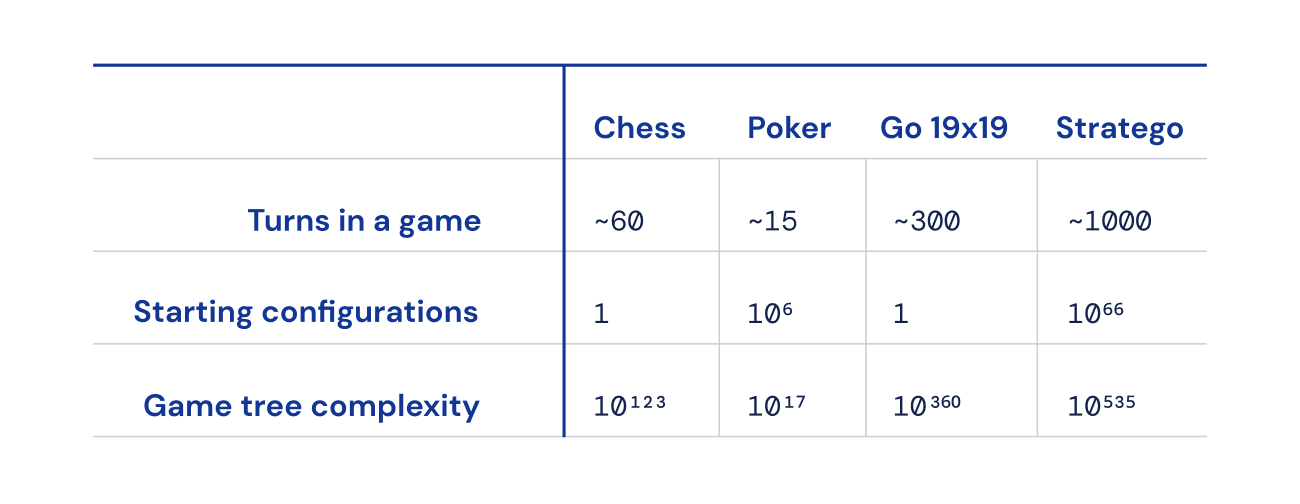
Исторически настольные игры были мерилом прогресса в области ИИ, позволяя нам изучать, как люди и машины разрабатывают и реализуют стратегии в контролируемой среде. В отличие от шахмат и го, Стратего — это игра с неполной информацией: игроки не могут напрямую наблюдать за фигурами противника.
Эта сложность означает, что другие системы Stratego на основе ИИ изо всех сил пытались выйти за рамки любительского уровня. Это также означает, что очень успешная техника искусственного интеллекта под названием «поиск по дереву игр», которая ранее использовалась для освоения многих игр с полной информацией, недостаточно масштабируема для Stratego. По этой причине DeepNash выходит далеко за рамки поиска по дереву игр.
Ценность освоения Stratego выходит за рамки игр. Преследуя нашу миссию по решению проблемы интеллекта для развития науки и на благо человечества, нам необходимо создавать передовые системы искусственного интеллекта, которые могут работать в сложных реальных ситуациях с ограниченной информацией о других агентах и людях. В нашей статье показано, как DeepNash можно применять в ситуациях неопределенности и успешно сбалансировать результаты, чтобы помочь решить сложные проблемы.
Знакомство со Стратего
Stratego — пошаговая игра с захватом флага. Это игра блефа и тактики, сбора информации и тонкого маневрирования. И это игра с нулевой суммой, поэтому любой выигрыш одного игрока представляет собой проигрыш такого же масштаба для его противника.
Stratego является сложной задачей для ИИ отчасти потому, что это игра с несовершенной информацией. Оба игрока начинают с того, что расставляют свои 40 игровых фишек в любом начальном порядке, который им нравится, изначально скрыты друг от друга в начале игры. Поскольку оба игрока не имеют доступа к одним и тем же знаниям, им необходимо взвесить все возможные результаты при принятии решения, что обеспечивает сложный ориентир для изучения стратегических взаимодействий. Типы фигур и их ранжирование показаны ниже.

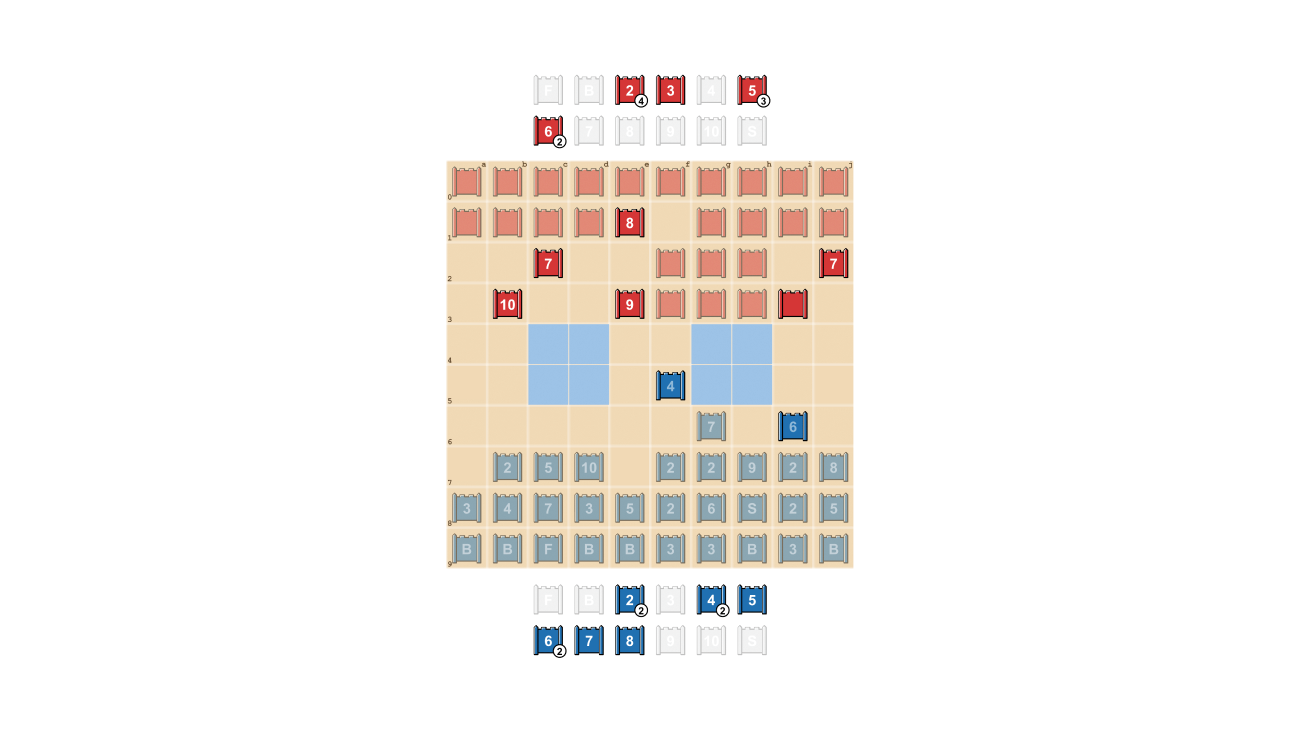
Середина: Возможная стартовая формация. Обратите внимание, как флаг надежно спрятан сзади, окруженный защитными бомбами. Две бледно-голубые области — это «озера», в которые никогда нельзя заходить.
Верно: Игра в игре, показывающая, как шпион Синих захватывает 10 красных.
Информация добывается с трудом в Stratego. Личность фигуры противника обычно раскрывается только тогда, когда она встречается с другим игроком на поле боя. Это резко контрастирует с играми с полной информацией, такими как шахматы или го, в которых местонахождение и идентичность каждой фигуры известны обоим игрокам.
Подходы к машинному обучению, которые так хорошо работают в идеальных информационных играх, таких как AlphaZero от DeepMind, нелегко перенести в Stratego. Необходимость принимать решения на основе неполной информации и возможность блефа сближает Stratego с покером техасский холдем и требует способностей, подобных человеческим, как однажды заметил американский писатель Джек Лондон: «Жизнь не всегда заключается в том, чтобы держать хорошие карты, но иногда хорошо разыграть плохую руку».
Однако методы искусственного интеллекта, которые так хорошо работают в таких играх, как техасский холдем, не переносятся в Stratego из-за огромной продолжительности игры — часто сотни ходов, прежде чем игрок выиграет. Рассуждения в Stratego должны выполняться по большому количеству последовательных действий без очевидного понимания того, как каждое действие способствует конечному результату.
Наконец, количество возможных состояний игры (выраженное как «сложность дерева игры») зашкаливает по сравнению с шахматами, го и покером, что делает решение невероятно трудным. Это то, что взволновало нас в Stratego и почему на протяжении десятилетий он представлял собой вызов сообществу ИИ.
В поисках равновесия
DeepNash использует новый подход, основанный на сочетании теории игр и глубокого обучения с подкреплением без моделей. «Без моделей» означает, что DeepNash не пытается явно моделировать частное игровое состояние своего оппонента во время игры. В частности, на ранних стадиях игры, когда DeepNash мало знает о фигурах противника, такое моделирование было бы неэффективным, если не невозможным.
И поскольку сложность дерева игр Stratego настолько велика, DeepNash не может использовать стойкий подход к играм на основе ИИ — поиск по дереву Монте-Карло. Поиск по дереву был ключевым элементом многих выдающихся достижений в области искусственного интеллекта для менее сложных настольных игр и покера.
Вместо этого DeepNash основан на новой теоретико-игровой алгоритмической идее, которую мы называем регуляризованной динамикой Нэша (R-NaD). Работая в беспрецедентном масштабе, R-NaD направляет поведение обучения DeepNash к так называемому равновесию Нэша (погрузитесь в технические детали в наша газета).
Игровое поведение, которое приводит к равновесию Нэша, не может быть использовано с течением времени. Если бы человек или машина играли в совершенно неэксплуатируемое Стратего, наихудший винрейт, которого они могли бы достичь, составил бы 50%, и только если он столкнулся с таким же совершенным противником.
В матчах против лучших ботов Stratego, в том числе нескольких победителей чемпионата мира Computer Stratego, процент побед DeepNash превышал 97%, а часто составлял 100%. Против лучших опытных игроков-людей на игровой платформе Gravon, DeepNash достиг коэффициента выигрыша 84%, что позволило ему войти в тройку лучших за все время.
Ожидать неожидаемое
Чтобы достичь этих результатов, DeepNash продемонстрировал несколько замечательных действий как на начальном этапе развертывания компонентов, так и на этапе игрового процесса. Чтобы их было трудно использовать, DeepNash разработала непредсказуемую стратегию. Это означает создание начального развертывания, достаточно разнообразного, чтобы противник не мог обнаружить закономерности в серии игр. А на этапе игры DeepNash рандомизирует между, казалось бы, эквивалентными действиями, чтобы предотвратить склонность к эксплуатации.
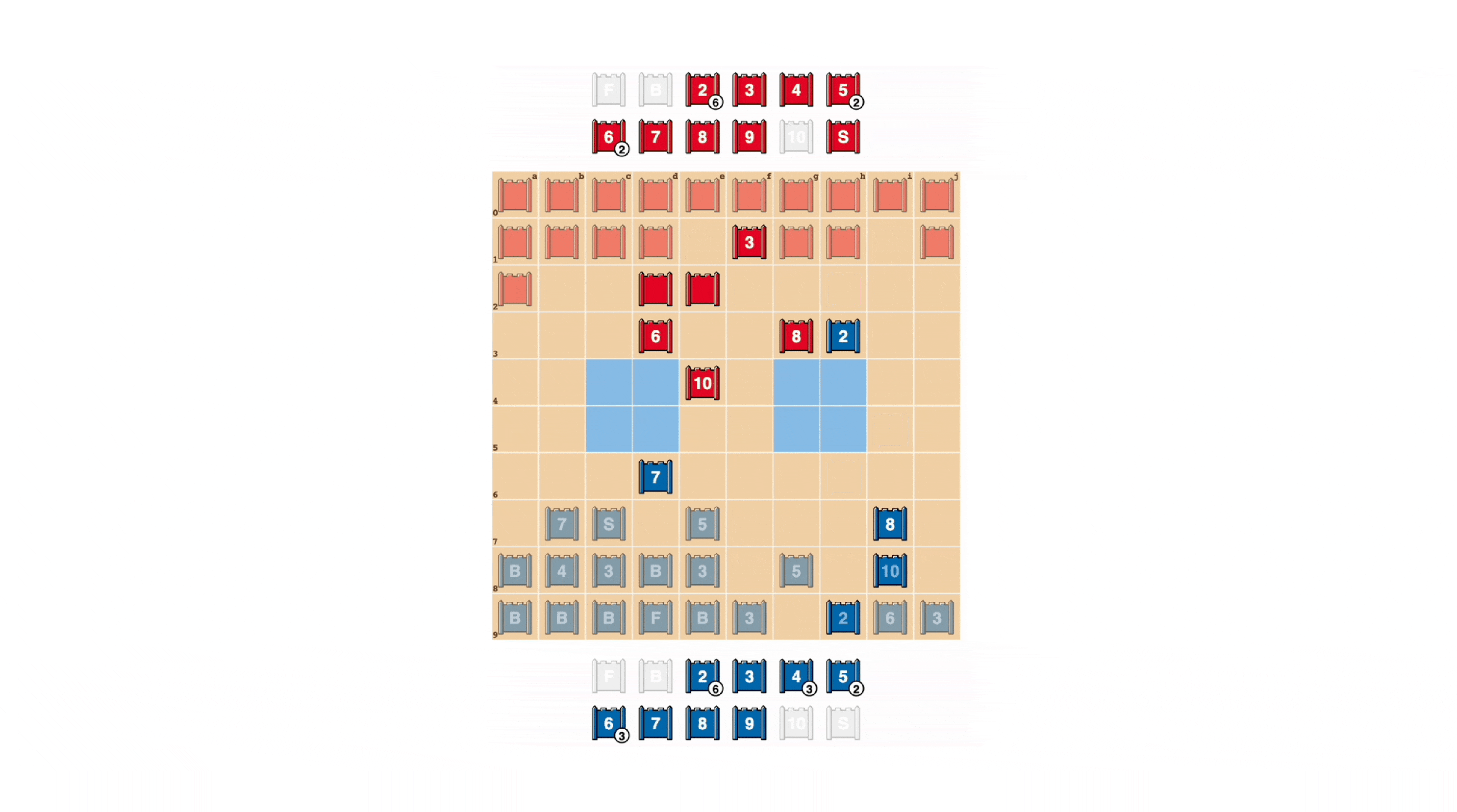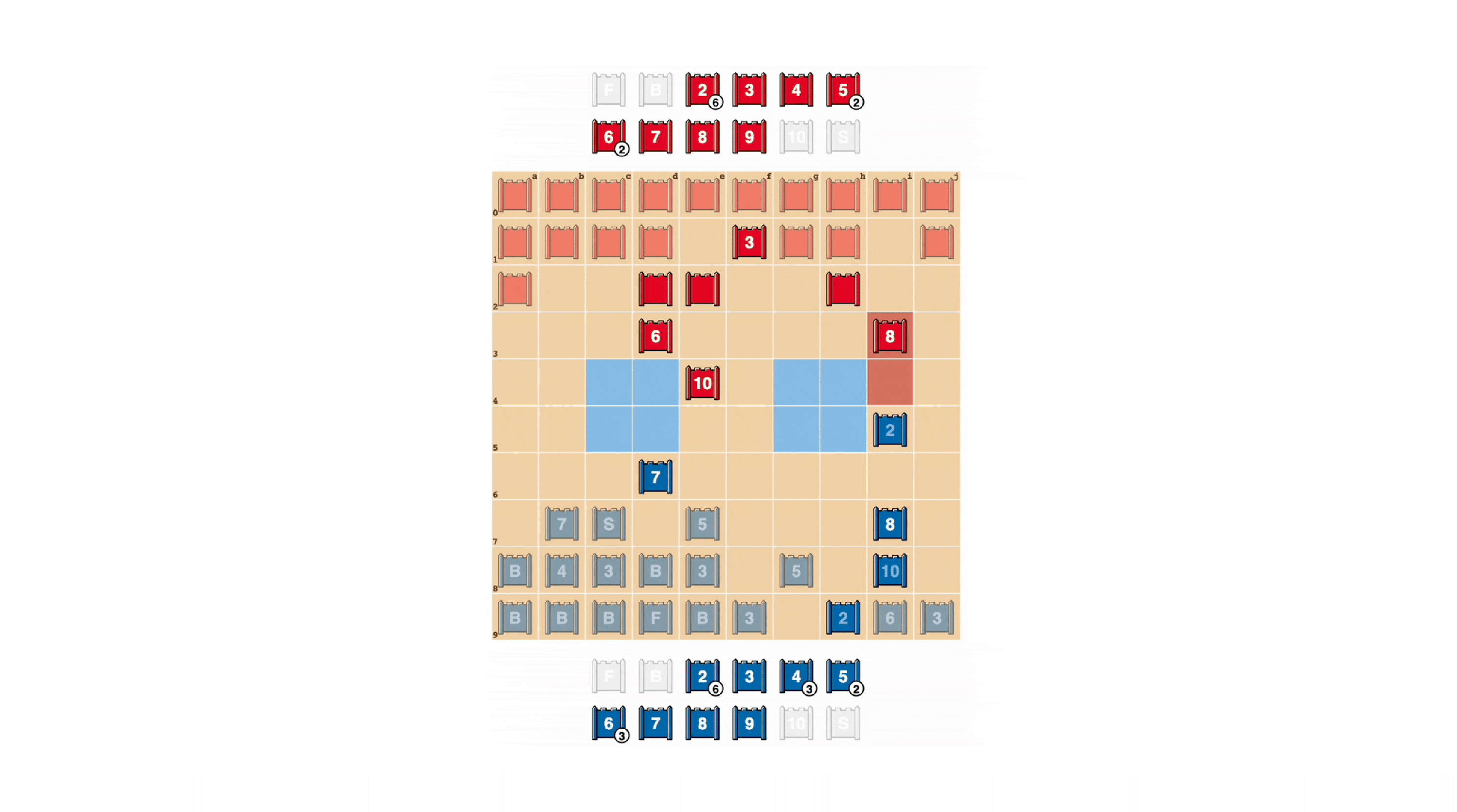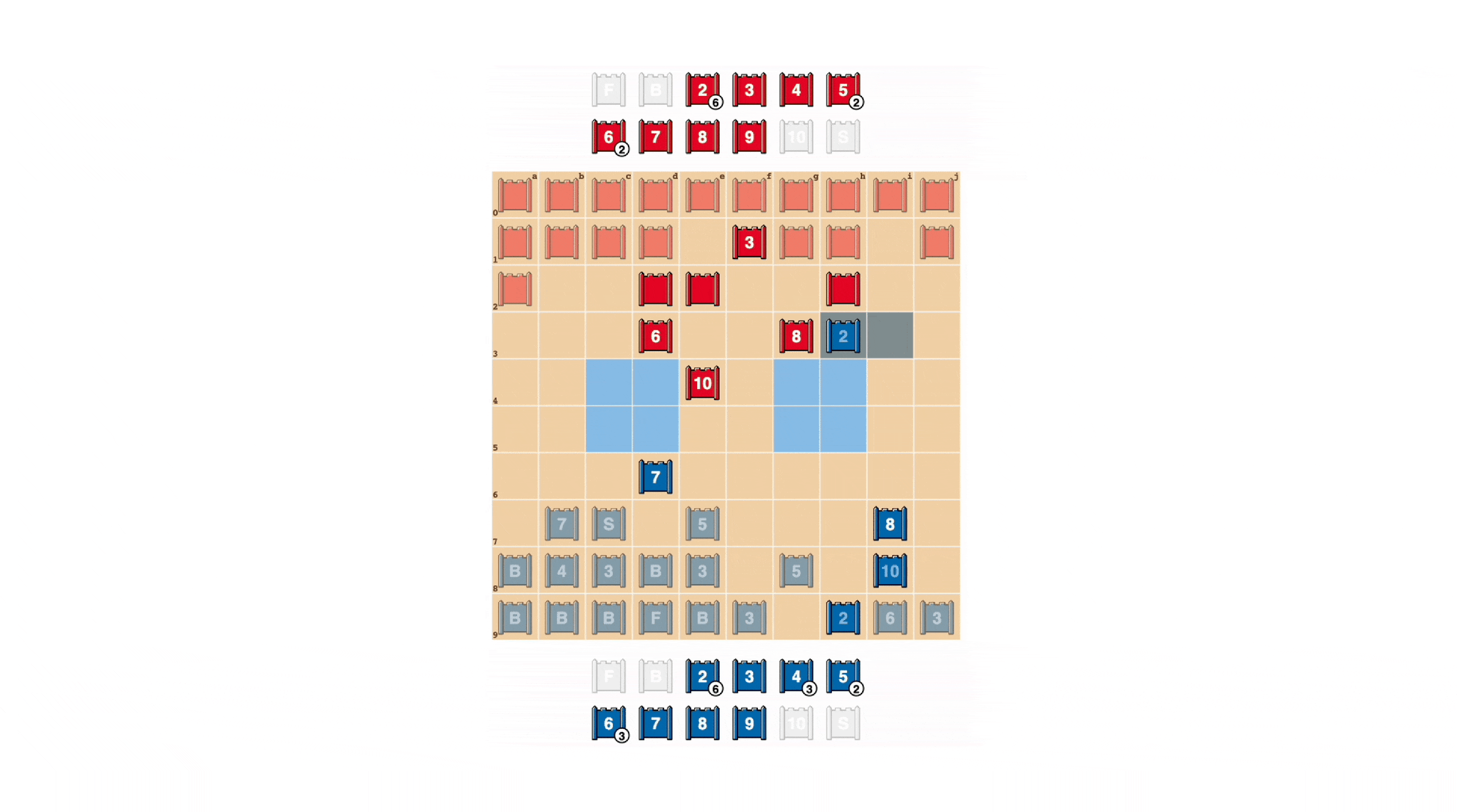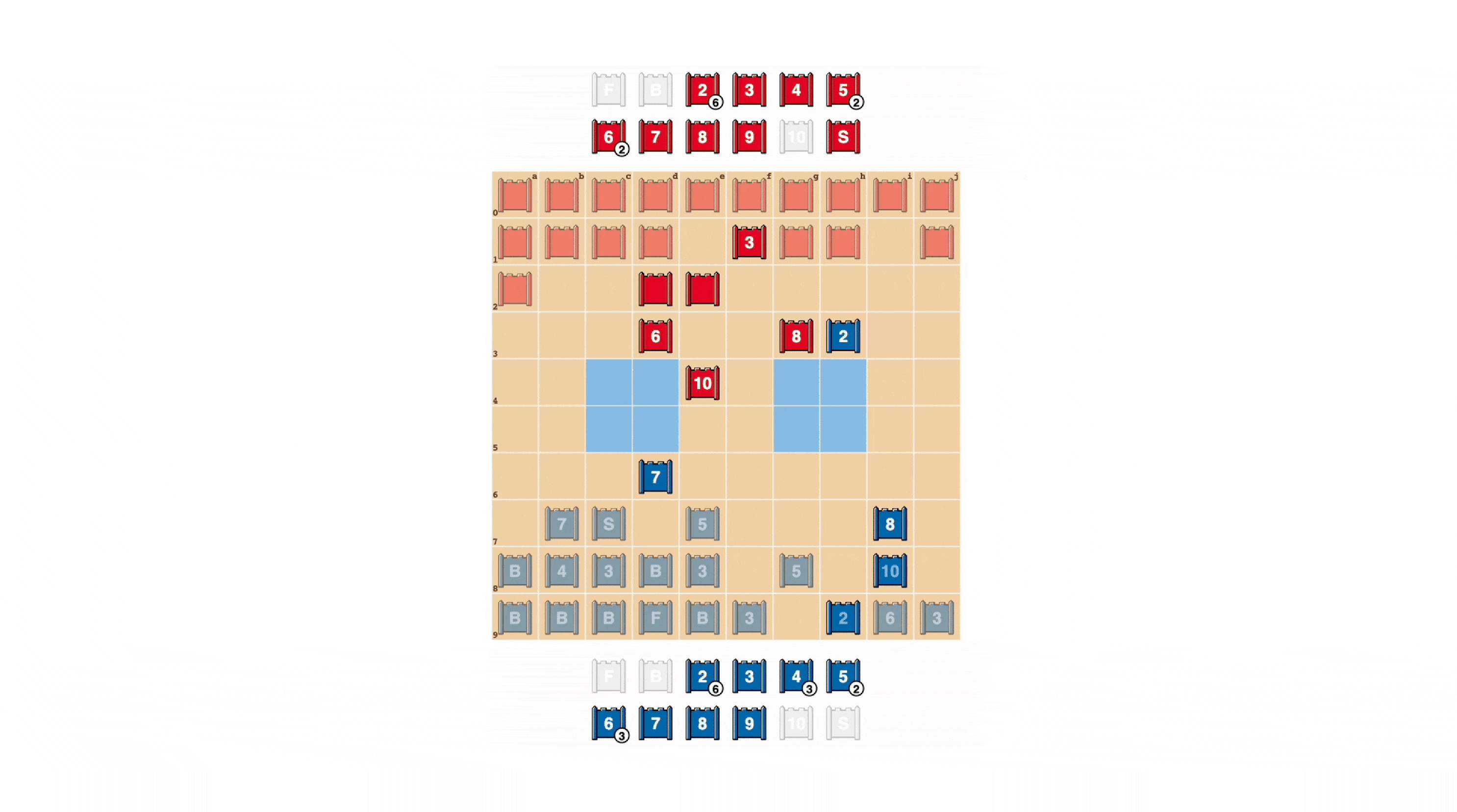
Игроки Stratego стремятся быть непредсказуемыми, поэтому важно скрывать информацию. DeepNash весьма поразительно демонстрирует, как он ценит информацию. В приведенном ниже примере против игрока-человека DeepNash (синий) пожертвовал, среди прочего, 7 (майор) и 8 (полковник) в начале игры и в результате смог найти 10 (маршал) противника. 9 (общий), 8 и две 7.
Эти усилия поставили DeepNash в невыгодное материальное положение; он потерял 7 и 8, в то время как его противник-человек сохранил все свои фигуры с рейтингом 7 и выше. Тем не менее, имея солидную информацию о высшем руководстве оппонента, DeepNash оценила свои шансы на победу в 70% — и победила.
Искусство блефа
Как и в покере, хороший Стратего иногда должен олицетворять силу, даже когда он слаб. DeepNash изучил множество таких тактик блефа. В приведенном ниже примере DeepNash использует 2 (слабый разведчик, неизвестный его противнику), как если бы это была фигура высокого ранга, преследуя известную 8 своего противника. чтобы заманить его в засаду своего шпиона. Эта тактика DeepNash, рискуя лишь незначительной фигурой, позволяет выманить и уничтожить шпиона противника, критическую фигуру.
Узнайте больше, посмотрев эти четыре видеоролика о полнометражных играх, сыгранных DeepNash против (анонимных) экспертов-людей: Игра 1, Игра 2, Игра 3, Игра 4.
«Уровень игры DeepNash меня удивил. Я никогда не слышал об искусственном игроке Stratego, который был бы близок к уровню, необходимому для победы в матче против опытного игрока-человека. Но после того, как я лично поиграл против DeepNash, я не был удивлен тем, что он позже занял первое место в рейтинге на платформе Gravon. Я ожидаю, что это будет очень хорошо, если им будет разрешено участвовать в чемпионатах мира среди людей».
– Винсент де Бур, соавтор статьи и бывший чемпион мира Stratego
Будущие направления
В то время как мы разработали DeepNash для строго определенного мира Stratego, наш новый метод R-NaD может быть непосредственно применен к другим играм с нулевой суммой для двух игроков как с идеальной, так и с неполной информацией. R-NaD может обобщать настройки, выходящие далеко за рамки игры для двух игроков, для решения крупномасштабных проблем реального мира, которые часто характеризуются несовершенной информацией и астрономическими пространствами состояний.
Мы также надеемся, что R-NaD поможет разблокировать новые приложения ИИ в областях, в которых участвует большое количество людей или участников ИИ с различными целями, которые могут не иметь информации о намерениях других или о том, что происходит в их среде, например, в большом масштабная оптимизация управления дорожным движением для сокращения времени в пути водителя и связанных с ним выбросов транспортных средств.
Создавая универсальную систему ИИ, устойчивую к неопределенности, мы надеемся расширить возможности ИИ по решению проблем в нашем изначально непредсказуемом мире.
Узнайте больше о DeepNash, прочитав наша статья в науке.
Для исследователей, заинтересованных в том, чтобы попробовать R-NaD или поработать с нашим недавно предложенным методом, мы открыли исходный код. наш код.