
Кажется, что каждые несколько месяцев кто-то публикует документ или демонстрацию по машинному обучению, от которой у меня отвисает челюсть. В этом месяце это новая модель генерации изображений OpenAI, ДАЛЛ·Е.
Эта гигантская нейронная сеть с 12 миллиардами параметров берет текстовую подпись (например, «кресло в форме авокадо») и генерирует изображения, соответствующие ей:

Из https://openai.com/blog/dall-e/.
Я думаю, что его изображения довольно вдохновляющие (я бы купил одно из тех кресел из авокадо), но что еще более впечатляет, так это способность DALL·E понимать и воспроизводить концепции пространства, времени и даже логики (подробнее об этом чуть позже). .
В этом посте я дам вам краткий обзор возможностей DALL·E, того, как он работает, как он сочетается с последними тенденциями в машинном обучении и почему он важен. Понеслось!
Что такое DALL·E и что он может делать?
В июле создатель DALL·E, компания OpenAI, выпустила такую же огромную модель под названием GPT-3, которая поразила мир своей способностью генерировать человекоподобный текст, включая обзоры, стихи, сонеты и даже компьютерный код. DALL·E — это естественное расширение GPT-3, которое анализирует текстовые подсказки и затем отвечает не словами, а картинками. Например, в одном примере из блога OpenAI модель визуализирует изображения из подсказки «гостиная с двумя белыми креслами и изображением Колизея. картина установлена над современным камином»:

Из https://openai.com/blog/dall-e/.
Довольно гладко, правда? Вероятно, вы уже видите, как это может быть полезно для дизайнеров. Обратите внимание, что DALL·E может генерировать большой набор изображений из подсказки. Затем изображения ранжируются по второй модели OpenAI, называемой КЛИПкоторый пытается определить, какие изображения подходят лучше всего.
Как создавался DALL·E?
К сожалению, у нас пока нет подробностей по этому поводу, потому что OpenAI еще не опубликовала полную статью. Но по своей сути DALL·E использует ту же самую новую архитектуру нейронной сети, которая отвечает за множество последних достижений в области машинного обучения: Трансформер. Трансформеры, обнаруженные в 2017 году, представляют собой простой в распараллеливании тип нейронной сети, который можно масштабировать и обучать на огромных наборах данных. Они были особенно революционны в обработке естественного языка (они лежат в основе таких моделей, как BERT, T5, GPT-3 и других), улучшая качество Поиск Гугл результатов, трансляции и даже предсказания структуры белков.
Большинство этих больших языковых моделей обучаются на огромных наборах текстовых данных (таких как вся Википедия или сканирование в Интернете). Что делает DALL·E уникальным, так это то, что он был обучен на последовательностях, которые представляли собой комбинацию слов и пикселей. Мы еще не знаем, что это был за набор данных (вероятно, он содержал изображения и подписи), но я могу гарантировать вам, что он, вероятно, был огромным.
Насколько «умным» является DALL·E?
Хотя эти результаты впечатляют, всякий раз, когда мы обучаем модель на огромном наборе данных, скептически настроенный инженер по машинному обучению вправе спросить, являются ли результаты высококачественными только потому, что они были скопированы или выучены из исходного материала.
Чтобы доказать, что DALL·E не просто извергает изображения, авторы OpenAI заставили его отображать несколько довольно необычных подсказок:
«Профессиональная высококачественная иллюстрация химеры черепахи-жирафа».

Из https://openai.com/blog/dall-e/.
«улитка, сделанная из арфы».

Из https://openai.com/blog/dall-e/.
Трудно представить, что модель столкнулась со многими гибридами жирафа и черепахи в своем наборе обучающих данных, что сделало результаты более впечатляющими.
Более того, эти странные подсказки намекают на нечто еще более захватывающее в DALL·E: его способность выполнять «нулевые визуальные рассуждения».
Визуальное мышление Zero Shot
Как правило, в машинном обучении мы обучаем модели, давая им тысячи или миллионы примеров задач, которые мы хотим, чтобы они выполнили, и надеемся, что они поймут шаблон.
Например, чтобы обучить модель, которая идентифицирует породы собак, мы можем показать нейронной сети тысячи изображений собак, помеченных по породам, а затем проверить ее способность маркировать новые изображения собак. Это задача с ограниченными возможностями, которая кажется почти странной по сравнению с последними достижениями OpenAI.
С другой стороны, обучение с нулевым выстрелом — это способность моделей выполнять задачи, для которых они не были специально обучены. Например, DALL·E был обучен генерировать изображения из подписей. Но с правильной текстовой подсказкой он также может преобразовывать изображения в эскизы:

Результат подсказки: «Тот же самый кот сверху, что и набросок снизу». Из https://openai.com/blog/dall-e/
DALL·E также может отображать пользовательский текст на дорожных знаках:

Результаты подсказки «Витрина магазина, на которой написано слово «openai»». Из https://openai.com/blog/dall-e/.
Таким образом, DALL·E может действовать почти как фильтр Photoshop, даже если он не был специально разработан для такого поведения.
Модель даже показывает «понимание» визуальных понятий (т. е. «макроскопические» или «поперечные» изображения), мест (т. е. «фото блюд из Китая») и времени («фото площади Аламо, Сан Франциско, с улицы ночью»; «фото телефона 20-х годов»). Например, вот что он выплюнул в ответ на подсказку «фото еды из Китая»:

«фото еды из Китая» с https://openai.com/blog/dall-e/.
Другими словами, DALL·E может сделать больше, чем просто нарисовать красивую картинку для подписи; он также может, в некотором смысле, отвечать на вопросы визуально.
Чтобы проверить способность DALL·E к визуальному мышлению, авторы заставили его пройти визуальный тест IQ. В приведенных ниже примерах модель должна была заполнить нижний правый угол сетки, следуя скрытому шаблону теста.
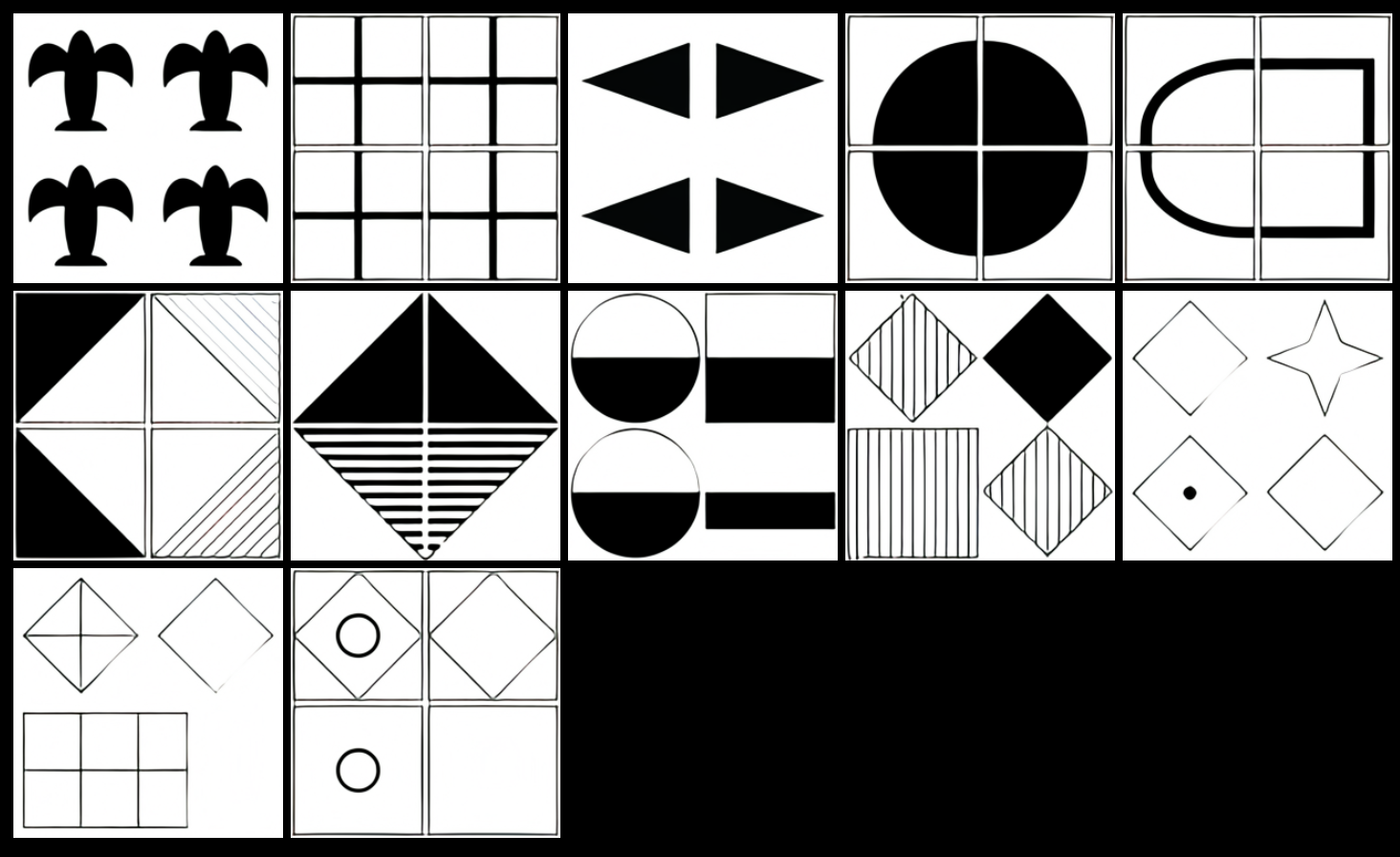
Скриншот теста визуального IQ, который OpenAI использовал для тестирования DALL·E. с https://openai.com/blog/dall-e/.
«DALL·E часто может решать матрицы, которые включают в себя непрерывные простые шаблоны или базовые геометрические рассуждения», — пишут авторы, но с некоторыми задачами он справлялся лучше, чем с другими. Когда цвета головоломок были инвертированы, у DALL·E дела обстояли хуже: «предполагая, что его возможности могут оказаться хрупкими неожиданным образом».
Что это значит?
Что меня больше всего поражает в DALL·E, так это его способность на удивление хорошо справляться со столькими задачами, о которых авторы даже не подозревали:
«Мы обнаружили, что DALL·E (…) может выполнять несколько видов задач преобразования изображения в изображение при правильном запросе.
Мы не ожидали, что эта возможность появится, и не вносили никаких изменений в нейронную сеть или процедуру обучения, чтобы стимулировать ее».
Это удивительно, но не совсем неожиданно; DALL·E и GPT-3 — два примера более важной темы глубокого обучения: необычайно большие нейронные сети, обученные на неразмеченных интернет-данных (пример «обучения с самоконтролем»), могут быть очень универсальными, способными делать множество вещей. не были специально предназначены для.
Конечно, не путайте это с общим интеллектом. Его не трудно чтобы обмануть эти типы моделей, чтобы они выглядели довольно глупо. Мы узнаем больше, когда они станут общедоступными, и мы сможем поиграть с ними. Но это не значит, что я не могу быть взволнован тем временем.