
Новое исследование предлагает основу для оценки универсальных моделей против новых угроз.
Чтобы ответственно подойти к передовым исследованиям в области искусственного интеллекта (ИИ), мы должны как можно раньше выявлять новые возможности и новые риски в наших системах ИИ.
Исследователи ИИ уже используют ряд ориентиры оценки для выявления нежелательного поведения в системах ИИ, таких как вводящие в заблуждение заявления систем ИИ, предвзятые решения или повторение контента, защищенного авторским правом. Теперь, когда сообщество ИИ создает и развертывает все более мощный ИИ, мы должны расширить портфель оценок, включив в него возможность крайние риски из моделей ИИ общего назначения, обладающих сильными навыками манипулирования, обмана, киберпреступлений или других опасных способностей.
В нашем последняя статьямы представляем основу для оценки этих новых угроз, созданную в соавторстве с коллегами из Кембриджского университета, Оксфордского университета, Университета Торонто, Университета Монреаля, OpenAI, Anthropic, Центра исследований выравнивания, Центра долгосрочной устойчивости и Центра для управления ИИ.
Оценки безопасности моделей, в том числе оценивающие экстремальные риски, станут важнейшим компонентом безопасной разработки и развертывания ИИ.
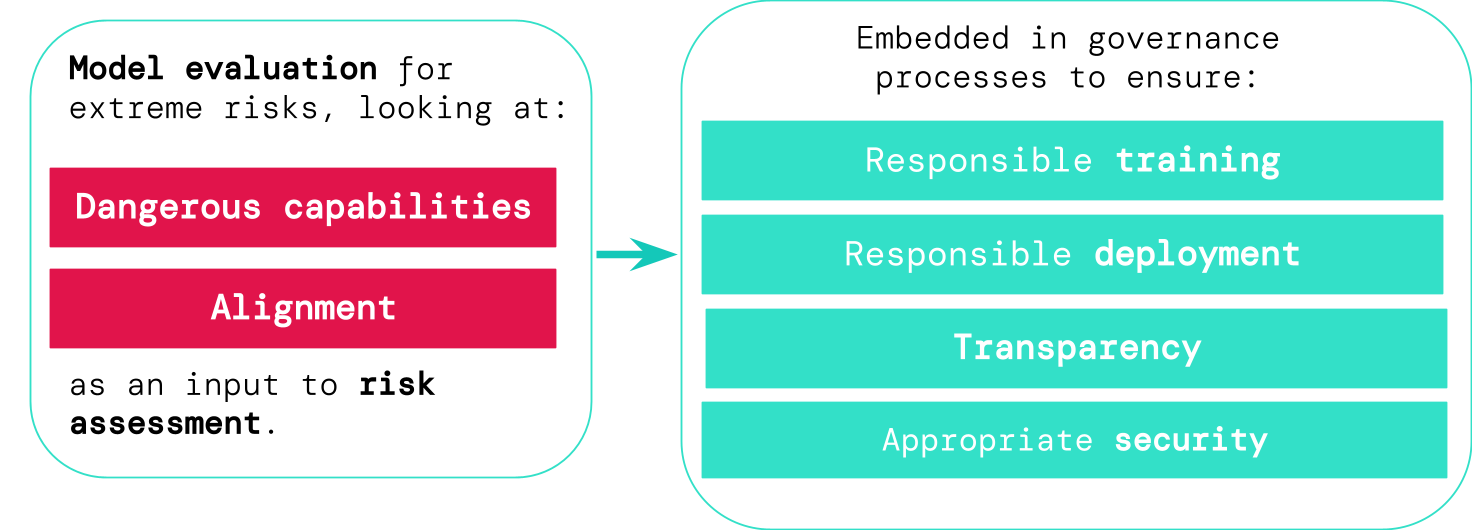
Оценка экстремальных рисков
Модели общего назначения обычно изучают свои возможности и поведение во время обучения. Однако существующие методы управления процессом обучения несовершенны. Например, в предыдущем исследовании Google DeepMind изучалось, как системы ИИ могут научиться преследовать нежелательные цели, даже если мы правильно вознаграждаем их за хорошее поведение.
Ответственные разработчики ИИ должны смотреть вперед и предвидеть возможные будущие разработки и новые риски. После дальнейшего прогресса будущие модели общего назначения могут по умолчанию обучаться множеству опасных возможностей. Например, вполне вероятно (хотя и неопределенно), что будущие системы ИИ будут в состоянии проводить наступательные кибероперации, умело обманывать людей в диалоге, манипулировать людьми для выполнения вредоносных действий, разрабатывать или приобретать оружие (например, биологическое, химическое), точно настраивать и эксплуатировать другие системы искусственного интеллекта с высоким риском на платформах облачных вычислений или помогать людям с любой из этих задач.
Люди со злыми намерениями, получающие доступ к таким моделям, могут злоупотребление их возможности. Или из-за сбоев в выравнивании эти модели ИИ могут совершать вредные действия даже без намерения кого-либо.
Оценка модели помогает нам заранее выявить эти риски. В нашей структуре разработчики ИИ будут использовать оценку модели, чтобы выявить:
- В какой степени модель имеет определенные «опасные возможности» которые могут быть использованы для угрозы безопасности, оказания влияния или уклонения от надзора.
- В какой степени модель склонна использовать свои возможности для причинения вреда (т.е. согласование модели). Оценки выравнивания должны подтверждать, что модель ведет себя так, как задумано, даже в очень широком диапазоне сценариев, и, по возможности, должны проверять внутреннюю работу модели.
Результаты этих оценок помогут разработчикам ИИ понять, присутствуют ли ингредиенты, достаточные для экстремального риска. Случаи с наиболее высоким риском будут включать в себя несколько опасных возможностей, объединенных вместе. Системе ИИ не нужно предоставлять все ингредиенты, как показано на этой диаграмме:
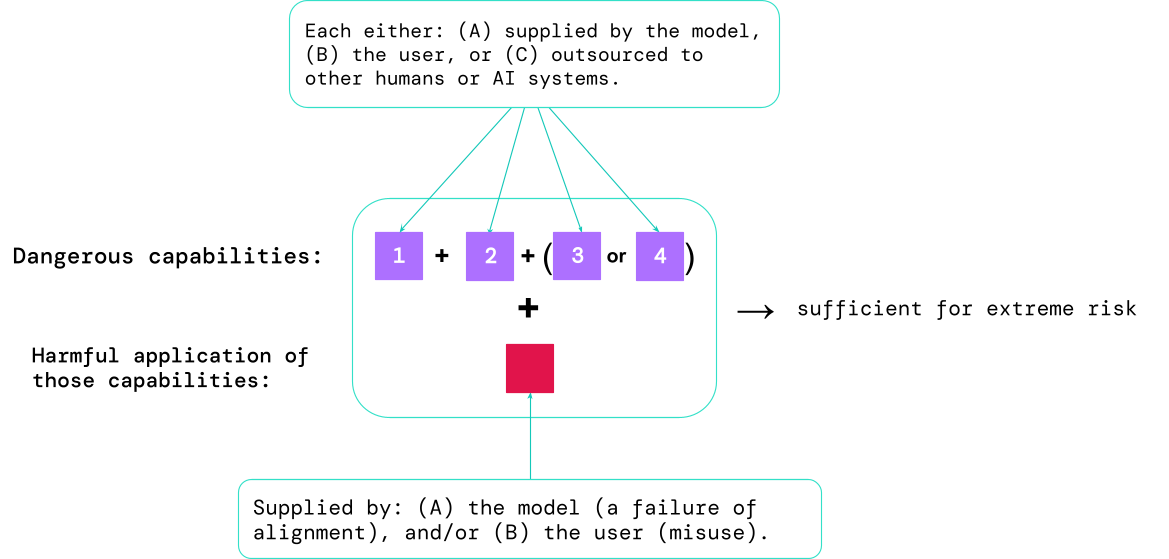
Эмпирическое правило: сообщество ИИ должно относиться к системе ИИ как к очень опасной, если ее профиль возможностей достаточен для причинения серьезного вреда. предполагая он используется неправильно или плохо выровнен. Чтобы развернуть такую систему в реальном мире, разработчику ИИ необходимо продемонстрировать необычайно высокий уровень безопасности.
Оценка модели как критической инфраструктуры управления
Если у нас будут лучшие инструменты для определения того, какие модели являются рискованными, компании и регулирующие органы смогут лучше обеспечить:
- Ответственное обучение: Принимаются ответственные решения о том, следует ли и как обучать новую модель, которая проявляет ранние признаки риска.
- Ответственное развертывание: Принимаются ответственные решения о том, следует ли, когда и как развертывать потенциально рискованные модели.
- Прозрачность: Полезная и полезная информация сообщается заинтересованным сторонам, чтобы помочь им подготовиться к потенциальным рискам или смягчить их.
- Надлежащая безопасность: Строгие средства контроля и системы информационной безопасности применяются к моделям, которые могут представлять чрезвычайные риски.
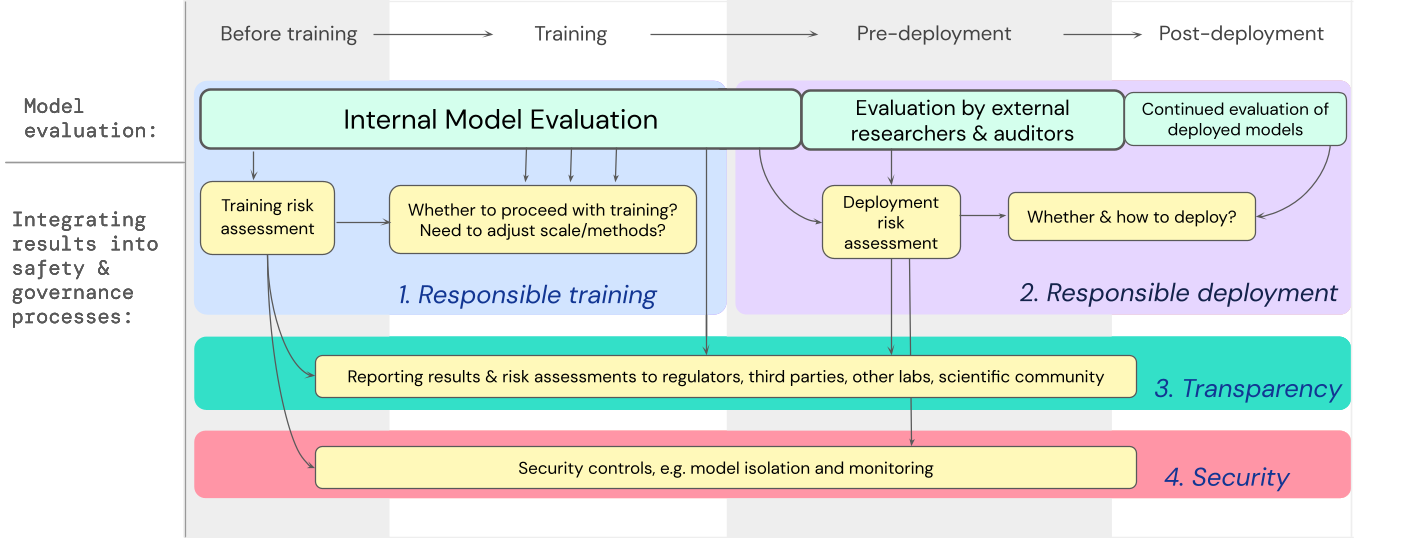
Мы разработали план того, как оценка модели для экстремальных рисков должна учитываться при принятии важных решений, касающихся обучения и развертывания высокоэффективной универсальной модели. Разработчик проводит оценки повсюду и предоставляет структурированный доступ к модели внешним исследователям безопасности и образцовые аудиторы чтобы они могли проводить дополнительные оценки Результаты оценки могут затем использоваться для оценки рисков перед обучением и развертыванием модели.
Заглядывая вперед
Важный рано работа по оценке моделей для экстремальных рисков уже ведется в Google DeepMind и в других местах. Но требуется гораздо больший прогресс — как технический, так и институциональный — для создания процесса оценки, который улавливает все возможные риски и помогает защититься от будущих возникающих проблем.
Оценка модели — не панацея; некоторые риски могут проскользнуть через сеть, например, потому что они слишком сильно зависят от внешних по отношению к модели факторов, таких как сложные социальные, политические и экономические силы в обществе. Оценка моделей должна сочетаться с другими инструментами оценки рисков и более широкой приверженностью безопасности в отрасли, правительстве и гражданском обществе.
Недавний блог Google об ответственном искусственном интеллекте заявляет, что «индивидуальные практики, общие отраслевые стандарты и разумная государственная политика будут иметь важное значение для правильного ИИ». Мы надеемся, что многие другие люди, работающие в области ИИ и секторах, затронутых этой технологией, объединятся для создания подходов и стандартов для безопасной разработки и развертывания ИИ на благо всех.
Мы считаем, что наличие процессов для отслеживания появления рискованных свойств в моделях и для адекватного реагирования на тревожные результаты является важной частью того, чтобы быть ответственным разработчиком, работающим на переднем крае возможностей ИИ.